|
|
[Suivant] [Précédent] [Fin] [Niveau supérieur]
Comme expliqué précédemment, l’inversion paramétrique est un processus permettant d’estimer des caractéristiques des éléments évalués à partir des acquisitions effectuées ou du moins de paramètres des signaux CF acquis. Deux types d’inversions existent : si le modèle utilisé est exécuté plusieurs fois, il s’agit d’une inversion itérative ; dans le cas contraire, l’inversion est directe.
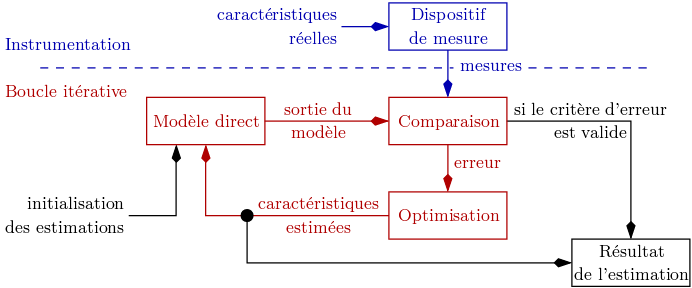
Pour l’inversion itérative, le processus est constitué d’une boucle d’itération au sein de laquelle se trouve le modèle direct, qui doit être connu, de façon exacte ou approchée. La sortie du modèle direct est comparée aux acquisitions effectuées, et l’erreur ainsi observée2 est proposée en entrée d’un algorithme d’optimisation qui modifie alors les estimations des caractéristiques recherchées. À chaque itération, cette modification a pour but de minimiser l’erreur obtenue. L’inversion est supposée correcte et le processus est arrêté lorsque cette erreur devient inférieure à une valeur limite déterminée comme critère d’arrêt des itérations. La figure 5.2 représente le schéma du processus d’inversion itérative.
Si toutes les méthodes d’inversion itératives répondent à ce schéma général, leur différence réside essentiellement dans l’algorithme d’optimisation qui effectue l’estimation des caractéristiques par modifications successives. De tels algorithmes sont relativement nombreux. Parmi les plus utilisés se trouvent la méthode de Newton[Deu04], la descente du gradient[Sny05], la méthode du simplexe[DOW55] ou encore les algorithmes génétiques[SBKKB07].
Un inconvénient de cette technique est le temps de calcul requis, en particulier si le modèle utilisé est complexe. En effet, les nombreuses itérations demandent un temps qui peut devenir important, et qui est inconnu a priori : chaque évaluation demandera un temps de traitement différent. Il est dès lors relativement difficile de mettre en œuvre ce genre d’inversion pour un système d’acquisition et de caractérisation simultanées.
De plus, l’inversion itérative est assez sensible à la précision du modèle direct : un modèle inexact peut aboutir à une solution non satisfaisante tandis qu’un modèle trop précis risque de rendre le processus peu robuste vis-à-vis de perturbations. Le choix de l’initialisation des caractéristiques estimées est aussi important. En effet, ces algorithmes d’optimisation recherchent des minima, et il arrive que le résultat soit un minimum local et non global. Cependant, des méthodes existent pour pallier ces problèmes, et l’inversion itérative est présentée comme une méthode très efficace et précise lorsque correctement mise en œuvre[SVS08].
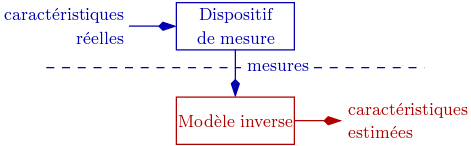
Dans le cas de l’inversion directe, le processus contient directement le modèle inverse, comme indiqué sur la figure 5.3. Deux cas se présentent alors.
Si le modèle direct est connu et inversible, le modèle inverse est alors obtenu par l’inversion du modèle direct. Le processus d’inversion est ensuite capable de donner de façon immédiate et systématique une estimation des caractéristiques du défaut inspecté. Cette méthode est donc particulièrement rapide. Il est envisageable3 que le modèle ne soit inversible que sur une plage réduite de valeurs, sur laquelle il aura été préalablement linéarisé[Akn90].
Si le modèle direct n’est pas inversible, le modèle inverse peut dans ce cas être construit à partir de la correspondance entre paramètres des signaux acquis et caractéristiques recherchées des défauts. Le modèle inverse n’a alors aucun rapport réel avec le modèle direct constitué des équations et lois physiques mises en jeu, mais les transformations qu’ils modélisent sont l’inverse l’une de l’autre. Il s’agit d’un modèle uniquement « comportemental », associant les variations des caractéristiques à estimer en fonction des paramètres des signaux. Ce modèle possède des paramètres internes, qui doivent être réglés par une période d’apprentissage.
Ces modèles inverses peuvent être établis par plusieurs algorithmes. Les algorithmes de type réseaux de neurones[SKC97, BCFR98] sont très utilisés, industriellement depuis une trentaine d’années. Inspirés des neurones biologiques, il s’agit d’un outil réputé souple, rapide et susceptible de modéliser des fonctions compliquées, notamment non linéaires. Cependant, un réseau de neurones possède, en plus de ses coefficients réglables, un grand nombre d’éléments variables. Il faut en effet déterminer en particulier le nombre de couches internes sur lesquelles sont fixés les neurones, le nombre de neurones sur chaque couche, le type de fonction d’activation pour chaque neurone. Toutes ces possibilités ont un revers : il est nécessaire de posséder une certaine expertise avant de pouvoir construire un réseau de neurones efficace.
Le choix entre les méthodes d’inversion brièvement présentées précédemment n’est pas évident. Les travaux de recherche des dernières décennies ont engendré une très grande diversité au sein de ces techniques, chacune présentant des avantages et des inconvénients.
Le choix dépendra avant tout du cahier des charges et de la précision du modèle direct. Il est possible d’effectuer un premier choix par le fait que si le temps de calcul n’est pas le principal critère et que le modèle direct est parfaitement connu, l’utilisation de méthodes itératives est souhaitable. Dans le cas d’une application rapide ou disposant de faibles moyens de calcul, les méthodes d’inversion directe sont préférables. La construction d’un modèle inverse sera obligatoire si le modèle direct n’est pas inversible.
2L’erreur entre les acquisitions réalisées et la sortie du modèle direct n’est pas nécessairement le résultat d’une simple soustraction ou d’un calcul d’erreur quadratique, mais peut intégrer des calculs plus complexes, comme ceux de fonctions de vraisemblance.
3Ces linéarisations sont même quasi-systématiques, au moins parce que l’ensemble des valeurs des grandeurs d’intérêt ne sont pas physiquement disponibles. Les modèles directs ne sont donc très souvent définis que sur une plage de valeurs finie, plage sur laquelle les grandeurs d’intérêt sont disponibles. Par ailleurs, le comportement des dispositifs d’acquisition en dehors de ces plages est souvent dénué d’intérêt.
[Suivant] [Précédent] [Début] [Niveau supérieur]